
What is the Right Service Granularity in APIs?
ByOlaf Zimmermann,Daniel Lubke,Cesare Pautasso,Mirko Stocker,Uwe Zdun
Date: Nov 17, 2022
Article is provided courtesy ofAddison-Wesley Professional.
Expert architects and developers present the EMBEDDED ENTITY and LINKED INFORMATION HOLDER API design patterns to help you represent referenced data in an API.
现实世界的api通常暴露和复杂的数据model parts such as Aggregates or Entities from a domain-driven design. Squeezing such complex, possibly nested data into a single JSON object in a HTTP request or response message is technically possible and often seen in practice, but might not always be an adequate choice. Many data elements contain references to others; for instance, think about orders and their order items or purchase orders referring to customers and products. An important question is how such references should be reflected in an API; answers to it determine the API endpoint and operation granularity, coupling characteristics, and other API qualities.
In this article, we present two API design patterns,EMBEDDED ENTITYandLINKED INFORMATION HOLDER, both eligible when deciding how to represent referenced data in an API. For more information and details on these two patterns (and 42 others), please refer to our bookPatterns for API Design: Simplifying Integration with Loosely Coupled Message Exchanges(Addison Wesley Signature Series).
Introduction to API Quality
Modern software systems are distributed systems. Mobile and Web clients exchange information with backend API services, often hosted by a single or even multiple cloud providers, and different backends trigger activities in each other. Independent of the technologies and protocols used, messages travel through one or several API clients and their service providers in such systems. This places high demands on quality aspects of each API implementation: API clients expect any published API to be developer-friendly, reliable, responsive, and scalable. API providers must balance conflicting concerns to guarantee high service quality while ensuring cost-effectiveness.
API quality patterns can help resolve the following overarching design issue:
How to achieve a certain level of quality of an offered API while at the same time cost-effectively utilizing the available resources?
可以说,很难找到API设计师nd product owners who do not value intuitive understandability, splendid performance, and seamless evolvability. That said, any quality improvement comes at a price—a literal cost such as extra development effort, but also negative consequences such as an adverse impact on other qualities. This balancing act comes from the fact that some of the desired qualities conflict with each other. Just think about the almost classic performance versus security trade-offs.
In this article, we are specifically interested in the following questions:
Is it preferable to exchange several small messages or a few larger ones?
Is it acceptable that some clients might have to send multiple requests to obtain all the data required so that other clients do not have to receive data they do not use?
Option 1: Nested Data
One option is to embed the content of the referenced data record in the data element sent over the wire:
| Pattern:EMBEDDED ENTITY | |
| Problem | How can one avoid sending multiple messages when their receivers require insights about multiple related information elements? |
| Solution | For any data relationship that the client wants to follow, embed aDATA ELEMENTin the message that contains the data of the target entity. |
This is a solution sketch forEMBEDDED ENTITY(note that all pattern names are set inSMALL CAPS):
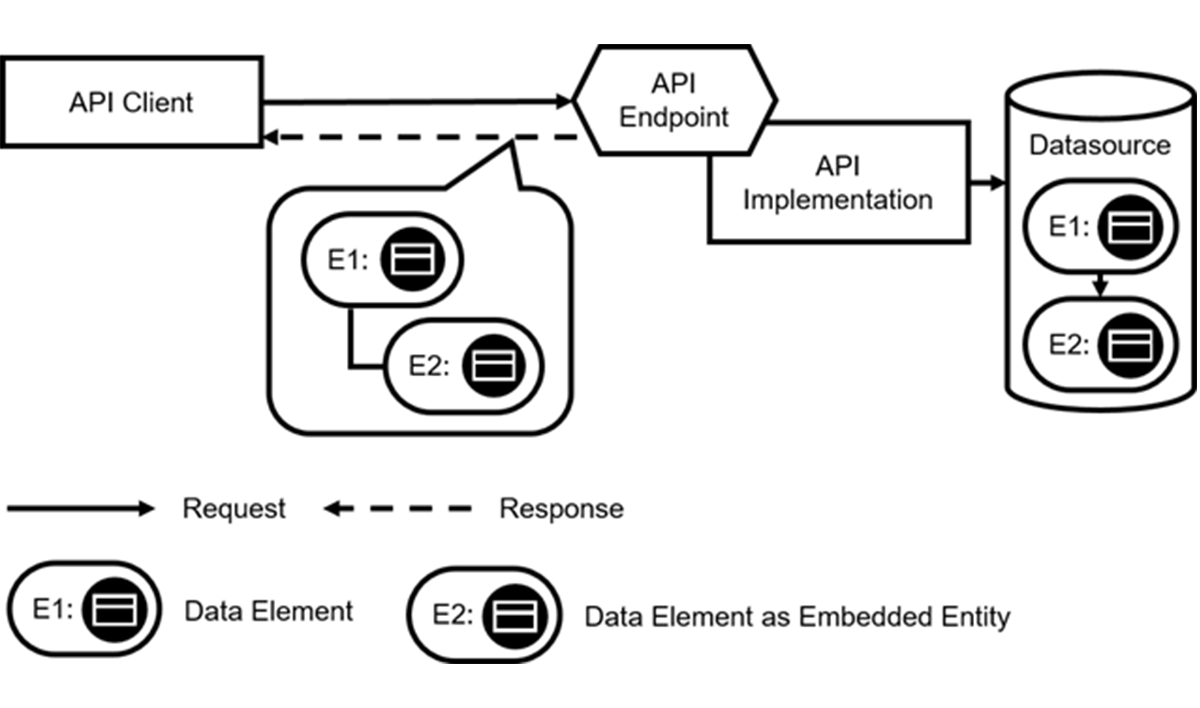
Click to view full-sized image
We discuss the pros and cons of this inclusive design later in this article (and in our book).
Option 2: Referenced Data
Another alternative is to make the reference data accessible remotely and reference it, introducing aLINK ELEMENTto the message:
| Pattern:LINKED INFORMATION HOLDER | |
| Problem | How can messages be kept small even when an API deals with multiple information elements referencing each other? |
| Solution | Add aLINK ELEMENTto messages that pertain to multiple related information elements. Let thisLINK ELEMENTreference another API endpoint that represents the linked element. |
The two-part message exchange resulting from applying theLINKED INFORMATION HOLDERpattern is sketched in the following figure:
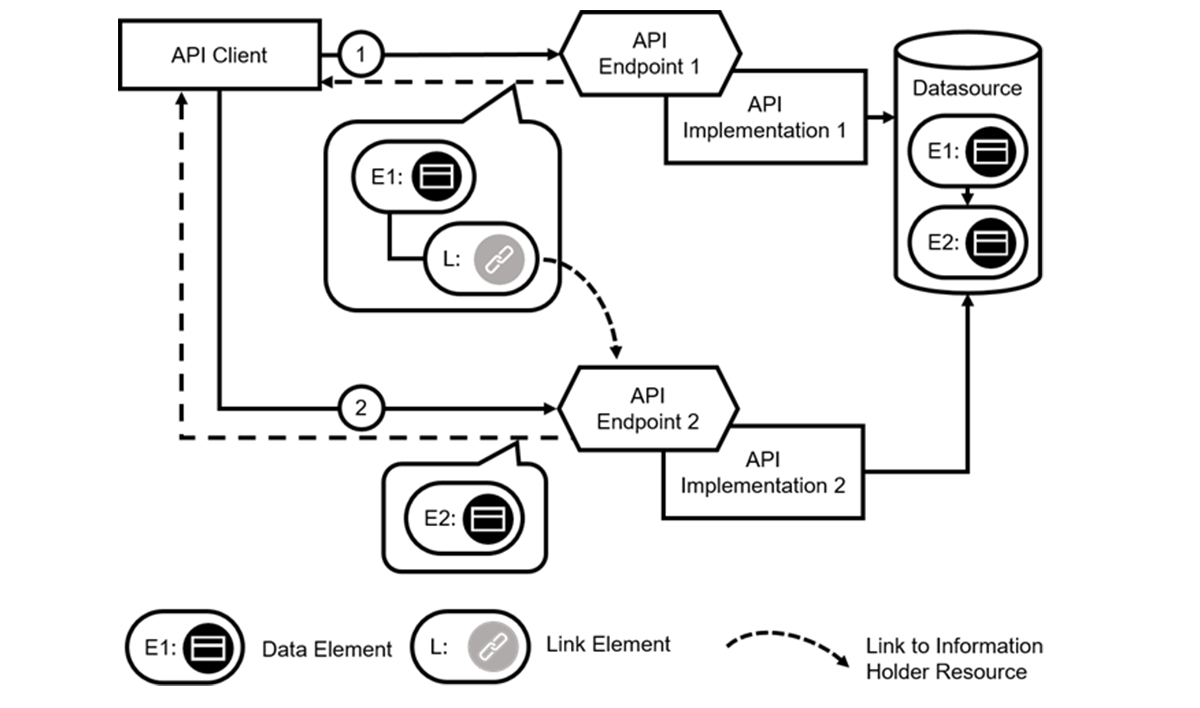
Click to view full-sized image
The application ofLINKED INFORMATION HOLDERleads to smaller messages that can refer to other API resources and, therefore, will lead to multiple round-trips to retrieve the same information. In the book, we discuss many more details, for instance how to deal with 1:n and n:m relationships in the API design.
Decision Drivers and Tradeoffs
Performance and scalability often play a significant role when deciding between these two patterns. Both message size and the number of calls required to perform an integration should be small, but these two desires conflict with each other. Modifiability and flexibility also have to be considered: information elements contained in structured self-contained data might be hard to change because any implementation-internal updates have to be coordinated and synchronized with updates to related request/response message structures and the API operations that send and receive them. Structured data that contains references to external resources usually is even harder to change than self-contained data as there are more consequences and (external) dependencies for clients.
EMBEDDED ENTITYdata sometimes gets stored on the receiver side for a while, whereas links always refer to the latest version of data. Thus, accessing data on demand via links is positive for data quality, freshness, and consistency. Regarding data privacy, a link source and target might have different protection needs—for example, a person and the credit card information belonging to this person. This has to be considered, for instance, before embedding the credit card information in a message requesting the person's data.
The decision to useEMBEDDED ENTITYmight depend on the number of message consumers and the homogeneity of their use cases. For example, if only one consumer with a specific use case is targeted, it is often good to embed all necessary data immediately. In contrast, different consumers might not work with the same data. To minimize message sizes, it might be advisable not to transfer all data all the time. The same organization might develop both client and provider. Embedding entities can be a reasonable strategy to minimize the number of requests in that case. In such a setting, they simplify development by introducing a uniform regular structure.
LINKED INFORMATION HOLDERis well suited when referencing rich information holders serving multiple usage scenarios: usually, not all message recipients require the complete set of referenced data, for instance, whenMASTER DATA HOLDERSsuch as customer profile managers or product record stores are referenced fromOPERATIONAL DATA HOLDERSsuch as customer inquiry agencies or order repositories. Following links toLINKED INFORMATION HOLDERS, message recipients can obtain the required subsets on demand.
There are several other relations between the patterns. They are related to the basic structural patternsDATA ELEMENTandLINK ELEMENT, which describe essential element roles in an API. In particular,LINKED INFORMATION HOLDERSuseLINK ELEMENTS, whereasEMBEDDED ENTITIESuseDATA ELEMENTS.
It is possible to combine the two patterns, for instance, when defining a top-levelEMBEDDED ENTITYthat containsLINKED INFORMATION HOLDERSfor (some of) its referenced data records. Combining linking and embedding data often make sense, for instance, embedding all data immediately displayed in a user interface and linking the rest for retrieval upon demand. The linked data is fetched only when the user scrolls or opens the corresponding user interface elements.
The Book: 29 Architectural Decisions and 44 API Design Patterns
EMBEDDED ENTITYandLINKED INFORMATION HOLDERkick off Chapter 7 of our book Patterns for API Design. The patterns in the book capture proven solutions to design problems commonly encountered when specifying, implementing and maintaining message-based APIs. They focus on message representations – the payloads exchanged when APIs are called. These payloads vary in their structure as API endpoints and their operations have different architectural roles and responsibilities. The chosen representation structures strongly influence the design time and runtime qualities of an API. The evolution of API specifications and their implementations has to be governed as well.
Part 1 of the book features an introduction to API fundamentals, a domain model for APIs, and a decision model identifying pattern selection questions, options, and criteria (six narratives guiding through the conceptual level of API design, with 29 recurring decisions). Part 2 presents the patterns in depth, grouping them into various themes and categories as shown in the following figure:
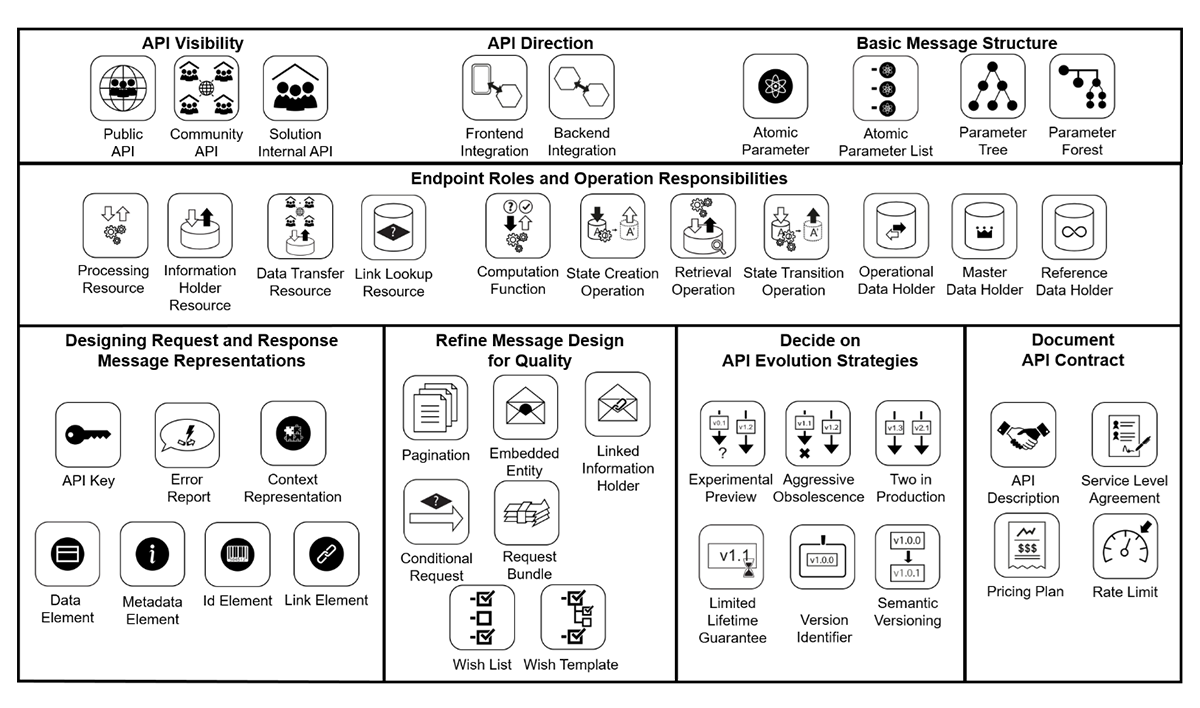
Click to view full-sized image
The book also applies the patterns to three cases, our fictitiousLakeside Mutualmicroservices scenario and two real-world projects that have been running in productions for some time. It presents an introduction to theMicroservice Domain Specific Language (MDSL)in one of three appendices; the other two provide a pattern eligibility cheat sheet and an implementation of selected Lakeside Mutual APIs.